
BERTとは何でしょうか? またBERTで何ができるのでしょうか?
BERTとは?
Google社 の Jacob Devlin と彼の同僚によって2018年に公開された自然言語処理の手法です。発表当時、多くの自然言語処理タスクでトップの性能を達成しました。
実際、Googleの検索業務でもBERTが活用されていて、2019年にはアメリカの英語検索クエリにBERTモデルを活用しているとGoogle社から発表しています。
BERT以前にも自然言語処理タスクで利用できるモデルはありましたが、BERTではTransformerという仕組みを使っているのがポイントです。このTransformer登場以降、従来自然言語処理の分野で利用されていたLSTMといった回帰ニューラルネットワークモデルにとって代わってTransformerが自然言語処理の分野で主役に躍り出ました。
BERTの大きな強みとして、一つのモデルで様々なタスクの処理ができるようになりました。まず大量のラベルなしデータを使って事前学習を行い、汎用的なモデルを生成します。そのあとに、特定タスクに特化したラベルありデータを使ってファインチューニングを行い、特定タスクに対する精度を向上させることができます。従来は特定タスクごとに1から事前学習を行う必要があり、大量のラベルありデータが必要でした。この課題をBERTは解決したのです。
また、自然言語処理の分野ではWord2Vec、Doc2Vecなどの手法が利用されていましたが、BERT以降はTransformerを利用するのが主流となっており、T5、GPT-1/2/3でもこのTransformerが利用されています。
このTransformerは様々な分野で活用されており、自然言語処理の分野にとどまらず画像認識タスクでも従来のCNNを凌駕するパフォーマンスを発揮しています。
BERTで何ができるのか?
BERTを利用した事例としては以下があります。
- チャットボット
- 自動FAQ作成
- 文書分類
- など
チャットボットなどはこれまでもありましたが、従来はボットが回答するロジックや文章を人間が登録していました。ただし、ロジックを考える時間や手間暇がかかるという問題がありました。
それがBERTは自分自身がデータを学習することによりロジックを組み立てて、回答文も自動で出力してくれるようになりました。
BERTの仕組み
以下の2段階の学習フェーズがあります。
- 事前学習・・・ 大量のラベルなしデータを使って学習を行います。
- ファインチューニング・・・ 特定の自然言語処理タスクに特化するようにラベルありデータを学習させて、特定タスクにおけるパフォーマンスをアップします。
まず、大量のデータを使って事前学習を行い、特徴量をつかんでおいて、そのあとに特定タスクに最適化できるように少量のラベル付きデータをファインチューニングして、特化したタスクでパフォーマンスアップを目指すイメージになります。
事前学習では、ラベルなしのデータを使って学習することになりますが、ラベルなしデータは大量に集めやすいというメリットがある反面、「何を学習させればいいか」の基準が難しいという側面があります。そこで一工夫が必要となります。
BERTは文章を双方向(左→右、右→左)に学習させるため以下2つの手法を使います。従来の自然言語処理モデルは、文章を単一方向で学習させることしかできませんでしたが、Transformerでは双方向に学習することにより、従来のモデルから飛躍的に性能が向上しています。
また文章を先頭から順番に逐次処理する必要がなく、従来型の自然言語処理モデルと比較して並列処理が可能となり、学習時間も圧倒的に短くなっています。
Masked Language Model(MLM)
BERTでは特定の単語から、その周辺の単語を予測して学習を行います。
まずデータのうちランダムに選ばれた15%のトークンを「MASK」トークンに置き換えます。そのあと、「MASK」トークンの場所に本来入っていたトークンは何か?という予測を行うことで学習を行います。
「明日ハンバーガーを食べたい」であれば
「CLS」、「明日」、「MASK」、「を」、「食べたい」、「SEP」
と「ハンバーガー」部分を「MASK」に置き換えて、その「MASK」はもともと何だったのか?という予測を行って学習します。
補足をすると、実際には選ばれた15%のうち、「MASK」というトークンにおきかえられるのが80%、10%をランダムに選ばれた他のトークンに、残りの10%はそのままにします。
そうすると、15%のうちそのままにしているのが10%あるのであれば、「15%ランダムにMASKする」といえないような気もしますよね。(これは想像ですが、当初は本当に15%をすべて「MASK」にしていた名残なのかもしれません)
BERTの論文内容を確認したい人はこちら↓

Next Sentence Prediction(NSP)
単語間の関連性は前述のMLMで学習できますが、自然言語処理タスクの中には文章同士の類似度、関連性を把握したい場合があります。2つの文章の関連性を学習するために、Next Sentence Prediction(NSP)という学習を行っています。
事前学習時、BERTは2つの文章のペアが入力されています。そして50%の割合でペアのうち片方の文章を別のランダムに選ばれた文章を配置します。そのあと、入力された2つの文章が連続したものかそうでないものかを判定し学習を行います。
この学習によって文章どおりの関連性が学習できるのです。
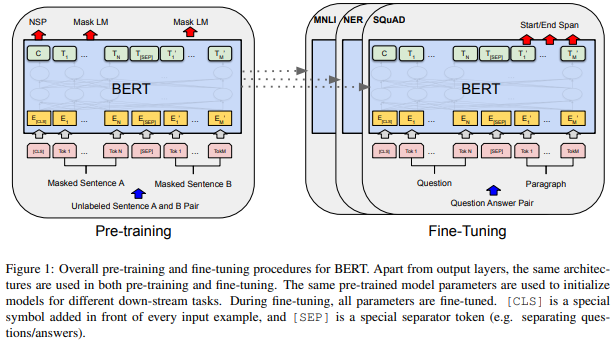
前述の2つの学習イメージが論文の図でいうところの以下の部分になります。BERTではこの2つの学習を組み合わせて行うことにより、従来の自然言語処理タスクと比較して圧倒的なパフォーマンスを得ることができるようになりました。
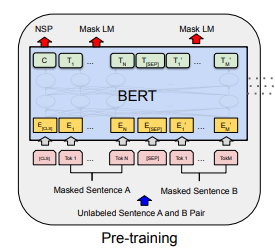
BERTの課題
自然言語処理業界に大きなブレークスルーをもたらしたBERTですが、いくつか課題があります。
つづく


コメント