はじめに
自然言語処理分野で大きなブレークスルーとなったTransformerについてまとめました。
話題のChatGPTでも使われている技術です。
Transformerとは何か?
Transformerは、自然言語処理や言語モデリングなどのタスクにおいて、驚くほど良い成果を出す深層学習モデルです。
Transformerの特徴
Transformerは、以下のような特徴を持っています。
- Attentionと呼ばれる機構を使用して、長いシーケンスを処理することができる。
- エンコーダーとデコーダーの2つの部分から構成される。
- 非常に高速であり、GPUを使用して学習することができる。
Transformerの応用例
Transformerは、以下のような応用例があります。
- 機械翻訳
- 要約
- 質問応答
- 文章生成
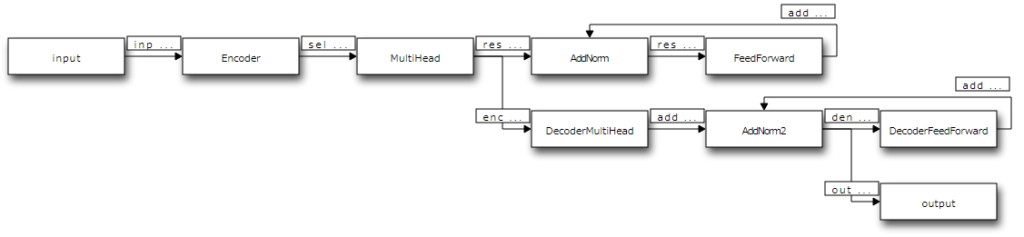
Transformerの仕組み
Transformerは、エンコーダーとデコーダーの2つの部分から構成されます。
エンコーダー
エンコーダーは、入力されたシーケンスをベクトルに変換するために使用されます。エンコーダーは、以下のような仕組みで構成されています。
- 入力シーケンスを単語ベクトルに変換する。
- Positional Encodingを追加する。
- Self-Attentionを計算する。
- Feed-Forward Networkを通す。
デコーダー
デコーダーは、エンコーダーが生成したベクトルをシーケンスに変換するために使用されます。デコーダーは、以下のような仕組みで構成されています。
- 出力シーケンスを単語ベクトルに変換する。
- Positional Encodingを追加する。
- Self-Attentionを計算する。
- Encoder-Decoder Attentionを計算する。
- Feed-Forward Networkを通す。
Attentionの仕組み
Transformerの重要な機能の1つであるAttentionは、ある単語に着目して、その単語に関連する他の単語の重要度を計算することで、より長い文脈を把握することができます。Attentionは、以下のような仕組みで計算されます。
- Query、Key、Valueと呼ばれる3つのベクトルを生成する。
- QueryとKeyの内積を計算する。これにより、QueryとKeyの類似度が得られます。
- 類似度をsoftmax関数に通すことで、重要度が得られます。
- 重要度とValueをかけ合わせて、重み付きのValueの合計を計算します。これにより、着目した単語に関連する他の単語の情報が考慮されたベクトルが得られます。
Transformerの学習方法
Transformerの学習は、通常の深層学習モデルと同様に、誤差逆伝播法による勾配降下法を使用します。しかし、Transformerは、大量のデータを使用することが必要であり、そのためにはGPUを使用することが必要です。
また、Transformerは、学習中にDropoutやBatch Normalizationなどの一般的な正則化手法を使用しないことが特徴的です。代わりに、Layer Normalizationが使用されます。
Transformerの改良
Transformerは、その高い精度と高速性から、自然言語処理の分野で広く使用されています。しかし、その改良点も見つかっています。
- Multi-Head Attention: 単一のAttentionを複数の頭に分割し、それぞれの頭でAttentionを計算することで、より豊富な情報を獲得できます。
- Pre-training: 大規模なコーパスを使用して、学習済みのモデルを作成することで、特定のタスクに対して転移学習を行うことができます。
- Transformer-XL: シーケンスの長さを考慮した改良版であり、長いシーケンスに対してより優れたパフォーマンスを発揮します。
以上が、Transformerの技術についての簡単な説明でした。より詳細な内容については、論文や書籍を参照することをおすすめします。
参考文献
- “Attention Is All You Need”論文: https://arxiv.org/abs/1706.03762
- “Illustrated Transformer”記事: https://jalammar.github.io/illustrated-transformer/
- “The Annotated Transformer”記事: https://nlp.seas.harvard.edu/2018/04/03/attention.html
- “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”論文: https://arxiv.org/abs/1810.04805
- “Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”論文: https://arxiv.org/abs/1901.02860
たね明かし
実はこの記事はChatGPTに教えてもらいました。
概要から非常にわかりやすく教えてくれるので、Webページを探し回る必要がなくなりました。
ChatGPTすごいです。


コメント